AI 降噪的底层逻辑:从“滤除”到“重建”
AI 降噪通过深度学习模型(主要是 CNN 和 Transformer 架构)识别并分离有用信号与背景噪声。其底层逻辑是利用大规模数据集训练,使算法能分辨出需要保留的“真实信息”与需要剔除的“干扰噪声”。
目前的 AI 降噪已从单纯的“滤除杂音”进化到“信号重建”。无论是图像的高 ISO 噪点还是音频的环境底噪,AI 不再是简单地抹平模糊区域,而是通过预测丢失的像素或频率来补充细节。这种能力的提升提高了后处理的容错率,使得在极端环境下拍摄或录音成为可能。
目前的 AI 降噪分化为两个方向:追求极致纯净的“工业级清理”和追求自然感的“艺术化保留”。
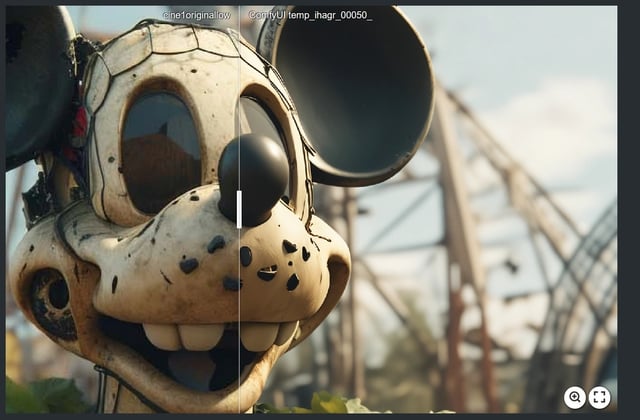
用户常误以为降噪数值越高越好,但过度处理会导致图像出现“塑料感”或音频出现“电音感”(Artifacts)。衡量工具好坏的标准,已从“能去掉多少噪声”转变为“在除噪的同时能保留多少原始信号的纹理和动态”。
图像与音频 AI 降噪的技术差异
图像 AI 降噪:基于 U-Net 的翻译
图像 AI 降噪基于 U-Net 架构的图像到图像翻译。模型通过学习数百万对“带噪”与“纯净”图像的对比,掌握了统计规律。例如,当像素点周围出现特定分布的随机色块时,算法会将其判定为高温下的热噪点而非真实纹理。使用 DxO PureRAW 或 Topaz Photo AI 时,软件实际上是在根据周围像素的逻辑推算该点在无噪声时的颜色,并用预测值进行替换。
音频 AI 降噪:频谱分析与掩蔽
音频 AI 降噪依赖频谱分析和掩蔽技术。它将声音从时间轴转换到频率轴,识别出空调低频嗡嗡声或键盘敲击声等特征,并生成动态掩蔽层精准切除。目前的实时降噪技术已能将处理延迟缩短至毫秒级,满足视频会议等实时场景的需求。
图像 AI 降噪专业工作流:预处理 $\rightarrow$ 精细化 $\rightarrow$ 局部还原
建议在进入调色软件前,先使用专门的 RAW 工具。操作路径:启动 DxO PureRAW $\rightarrow$ 导入 RAW 文件 $\rightarrow$ 开启“DeepPRIME XD2”引擎 $\rightarrow$ 输出为 DNG 格式。对于 ISO 6400 以下照片建议维持默认;ISO 12800 以上照片,强度滑块建议不超过 80%,以防细节丢失。务必开启“光学校正”,否则边缘畸变区域容易产生色彩晕染。若遇到 GPU 内存不足报错,请关闭其他显存占用程序或将计算加速切换至 CPU。
预处理后的照片若显得过于平坦,可用 Topaz Photo AI 找回细节。导入 DNG/TIFF 文件 $\rightarrow$ 在 Autopilot 面板手动开启“Remove Noise”和“Sharpen”。将“Remove Noise”强度设在 10-30 之间,将“Sharpen”设为 Standard 或 Strong 模式,Strength 控制在 20 左右并调小 Radius。若出现不自然的“虫迹”线条(AI 幻觉),请使用遮罩笔刷将效果从天空等纯色区抹除,仅保留在主体细节上。

AI 除噪后,照片对比度和饱和度可能微降。在 Lightroom 中微调曝光与对比度,并在“效果”面板增加 5-10 个单位的“纹理”以抵消塑料感。若导出后噪点回升,通常是因为在 LR 中过度拉高阴影导致量子噪声被放大,此时应返回第一步增加预处理强度。
音频 AI 降噪专业工作流:静态清理 $\rightarrow$ 动态分离 $\rightarrow$ 谐波补偿
先处理恒定噪声(如电流声)。在 DAW 中选取 2-3 秒无声片段 $\rightarrow$ 使用 iZotope RX 或 UniConverter AI 的“Learn”功能学习频谱特征 $\rightarrow$ 应用到全轨。Reduction 数值建议在 6dB 到 12dB 之间,避免出现“水下感”。若人声被误判,可通过“频谱编辑”手动将 100Hz - 5kHz 频段排除在降噪区之外。
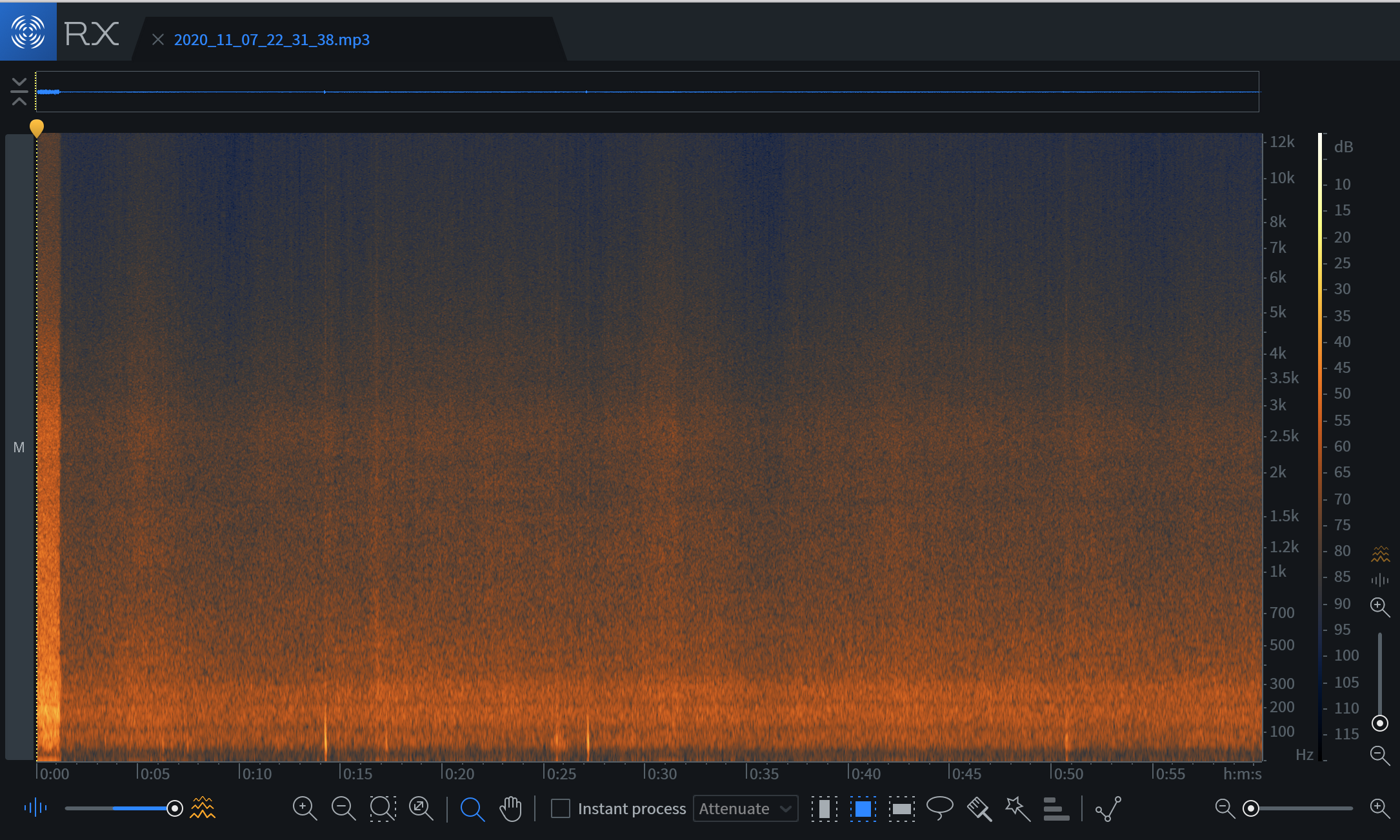
针对敲击声等不规律噪音,使用 Adobe Podcast Enhance 或 RX Voice De-noise 等深度学习工具。将“Mix”滑块设定在 70% - 80% 之间,保留 20% 原声可维持环境氛围,避免声音过于干燥。若出现金属质感,可降低处理强度并配合低通滤波器切掉 10kHz 以上的高频杂讯。
AI 降噪常会带走部分谐波,使声音单薄。在信号链末端加入轻微压缩器(Threshold -15dB, Ratio 2:1),随后使用激励器(Tube 或 Tape 模式)增加 1-2dB 高频谐波。最后检查峰值电平,确保在 -3dB 左右,避免数字削波。
AI 降噪的应用边界与工具对比
AI 降噪并非万能,在以下场景需谨慎使用:
- 艺术创作:追求胶片颗粒感或环境临场感时,过度除噪会抹杀情绪表达,使场景死寂。
- 证据/医疗领域:AI 的“预测与重构”可能产生幻觉,生成不存在的细节,在需要绝对真实性的场景下可能导致信息失真。
- 极低信噪比文件:当有用信号占比低于 10% 时,强行 AI 降噪易产生严重相位畸变,此时传统频谱编辑更可靠。
| 领域 | 工具 | 核心优势 | 适用人群 |
|---|---|---|---|
| 图像 | DxO PureRAW | 底层纯净度极高,RAW 级优化 | 专业摄影师 |
| Topaz Photo AI | 擅长后期补救与细节重建 | 内容博主 | |
| Adobe AI (LR/PS) | 集成度高,工作流无缝 | 综合设计师 | |
| 音频 | iZotope RX | 工业级精细修复,控制力强 | 混音师/音频工程师 |
| Adobe Podcast | 一键式处理,门槛极低 | 播客主/视频剪辑师 |
AI 降噪是否会改变原图/原音的真实性?
是的。AI 降噪在本质上是基于概率的“预测”而非简单的“滤除”。当强度过高时,AI 会用学习到的模式替换原始信号,从而产生所谓的“AI 幻觉”或失真。建议通过 Mix 滑块或遮罩控制,保留 10%-20% 的原始噪声以维持自然感。
为什么在 Lightroom 中拉高阴影后噪点又回来了?
因为 AI 降噪通常作用于特定亮度层级。当你强行拉高阴影时,原本被压制的量子噪声被同步放大,且此时 AI 预处理的覆盖范围不足以抵消这种指数级增长的噪点。最佳实践是在 RAW 预处理阶段就适当提高强度,而非在后期调色中过度拉伸。
未来的竞争焦点将是“上下文感知”——AI 能分辨雨夜的雨滴纹理与传感器的热噪点,或分辨演讲中的掌声与空调噪音。面对低质量素材,不要试图用一个滑块解决所有问题。采用“底层预处理 $\rightarrow$ AI 局部微调 $\rightarrow$ 传统工具找回质感”的混合工作流,是确保作品既纯净又真实的有效路径。