AI绘画的底层逻辑:从随机抽卡到精准控制
AI绘画的核心是通过扩散模型(Diffusion Models)或生成对抗网络(GANs)将文本转化为图像,其本质是在高维潜在空间中对概率分布进行采样并解码为像素。到2026年3月,该技术已从随机的“提示词抽卡”进化为可精准控制的工业级工具。这意味着核心竞争力已从“能否生成图像”转向“如何构建个体不可替代的审美壁垒”。
AI并非在替代绘画,而是在重新定义“画”这个动作。过去,绘画门槛是手眼协调的生理能力与长期训练;现在,门槛变成了对视觉语言的调度能力和最终结果的裁决权。这类似于19世纪摄影术的出现,它虽威胁到写实主义,却迫使绘画走向印象派和抽象主义,让艺术家从“捕捉现实”的使命中解脱出来。
理解潜空间(Latent Space)是掌控图像的关键

若要掌控图像而非依赖随机性,必须理解潜空间(Latent Space)。模型训练时将数亿张图片压缩为数学向量,输入“赛博朋克”时,AI实际上是在向量空间中定位坐标并还原特征。简单的词汇只能得到该坐标点的平均值,导致作品产生典型的“AI味”。打破这种平均感,必须依赖精细的参数控制和权重调节。
工业级AI绘画的深度实操路径
第一步:环境搭建

根据需求选择工具:追求便捷可选择 Midjourney v7,其光影理解仍处于领先地位;需要商业级控制则应部署 Stable Diffusion 的迭代版本。
配置显存 16GB 以上的 NVIDIA 显卡(如 RTX 4090) $\rightarrow$ 安装 Python 3.10 $\rightarrow$ 克隆 GitHub WebUI 或 ComfyUI 仓库 $\rightarrow$ 配置虚拟环境 $\rightarrow$ 安装依赖包 $\rightarrow$ 下载 Checkpoint 基础模型。
注意:若遇到 CUDA 版本不匹配导致显卡无法调用,应严格对照 NVIDIA 驱动版本号安装对应的 PyTorch 版本。
第二步:构建可控生成管线
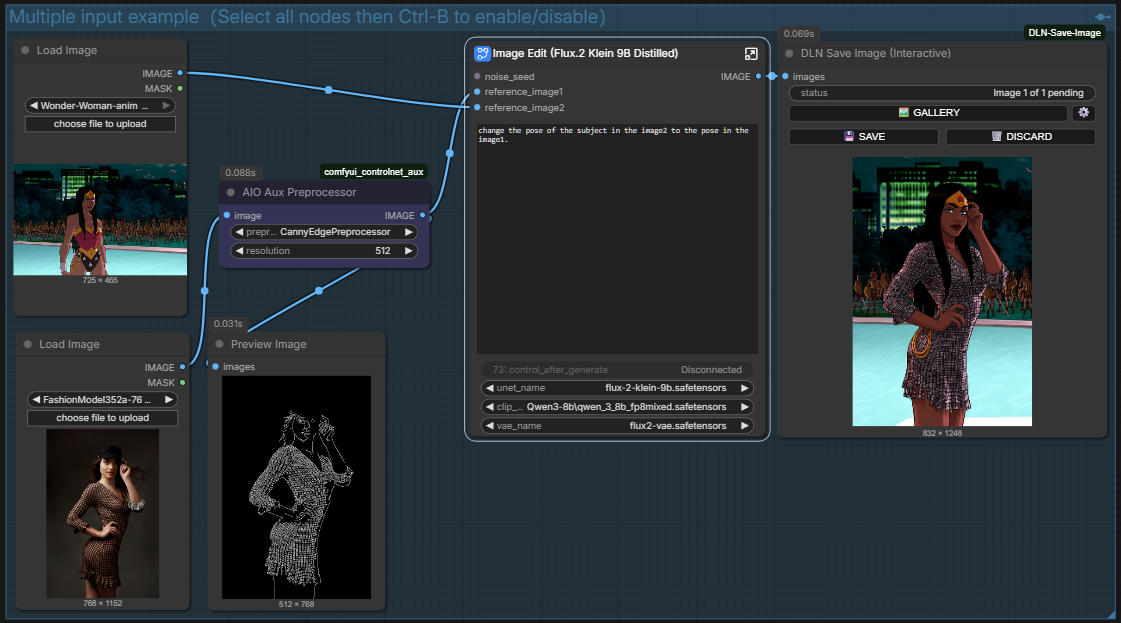
高效的逻辑是“基础底图 $\rightarrow$ 精确控制 $\rightarrow$ 局部重绘”,而非堆砌长提示词。通过结构化控制,将图像细节由“随机馈赠”转为“意图控制”。
2. 角色一致性:使用 Kohya_ss 训练 LoRA 模型,准备 20-50 张高质量参考图,学习率设为 1e-4,训练约 2000 步。
3. 细节迭代:利用 Inpainting 遮罩覆盖不满意区域,将重绘幅度(Denoising Strength)降至 0.4 左右进行局部微调。
第三步:整合数字化工作流

AI 生成图通常缺乏视觉重心,建议将 AI 作为生产环节而非最终结果,通过“AI生成+人工精修”的混合模式避免作品同质化。
AI 绘画与传统数字绘画的维度对比
AI 绘画在降低门槛的同时,也带来了阵痛。它剔除了仅将绘画视为技能习得的人,留下了对视觉表达有追求的人。AI 解决了“怎么画”,但无法决定“画什么”以及“为什么这么画”。

| 维度 | 传统数字绘画 | AI 绘画 |
|---|---|---|
| 成本 | 数千小时的练习时间 | 算力成本与审美迭代时间 |
| 效果 | 绝对掌控力与笔触情感 | 极高材质模拟,但易出现逻辑错误 |
| 风险 | 效率低、商业交付慢 | 版权纠纷与风格同质化 |
| 场景 | 顶尖艺术品、强个人风格插画 | 概念设计、原型迭代、电商背景 |
局限性分析与避坑指南
目前的 AI 绘画仍有明显局限,不能在所有场景下盲目替代。首先是空间逻辑缺失,在处理镜面投影或精确工业结构图时仍常出现“视觉欺骗”错误;其次是缺乏叙事语境,模拟的情感表达往往呈现出一种“精致的空洞感”。
不建议完全依赖 AI 的场景:
- 需要极高精确度的技术制图(如建筑施工图);
- 承载私人情感的日记绘画;
- 对版权纯洁度有极端要求、不希望被训练集污染的顶级商业定制。
如何消除AI绘画中常见的“AI味”?
核心在于打破概率分布的平均值。建议通过提高提示词的具体度、使用自定义 LoRA 模型引入非通用风格,并在后期通过 Photoshop 手动调整光影与色彩,打破算法生成的固有模式。
对于初学者,应该先学习提示词(Prompt)还是学习 ControlNet?
建议先掌握基础提示词以快速出图,但应尽早转向 ControlNet。因为提示词是“请求”,而 ControlNet 是“指令”,后者才是将 AI 转化为生产力工具的关键。
结语:从绘画者进化为“视觉导演”
面对变革,建议将自己定位为“视觉导演”。导演无需亲自搬摄像机,但必须决定镜头位置、光线方向与演员情绪。在 AI 绘画中,提示词是剧本,ControlNet 是分镜,而个人审美则是最终的剪辑权。
现在可以尝试构建第一个专属 LoRA 模型,或在 ComfyUI 中搭建自动化工作流,而非在对话框里重复尝试词汇。当你能掌控 AI 无法随机生成的视觉逻辑时,才真正拥有核心竞争力。